
Disruptive innovation, a concept introduced in 1995, has become a wildly popular concept explaining innovation-driven growth.
The Disruptive Innovation Model

Clayton Christensen’s “Disruptive Innovation Model” refers to a theory that explains how smaller companies can successfully challenge established incumbent businesses. Here’s a detailed breakdown:
 Disruptive Innovation refers to a new technology, process, or business model that disrupts an existing market. Disruptive innovations often start as simpler, cheaper, and lower-quality solutions compared to existing offerings. They often target an underserved or new market segment. They often create a different value network within the market. However, truly disruptive innovation companies improve over time and eventually displace existing market participants.
Disruptive Innovation refers to a new technology, process, or business model that disrupts an existing market. Disruptive innovations often start as simpler, cheaper, and lower-quality solutions compared to existing offerings. They often target an underserved or new market segment. They often create a different value network within the market. However, truly disruptive innovation companies improve over time and eventually displace existing market participants.
In fact, there are two general types of disruptive innovation models:
- Low-End Disruption: Targets the least profitable customers who are typically overserved by the incumbent’s existing offering.
- New-Market Disruption: Targets customers with needs previously unserved by existing incumbents. You may have heard of the “blue ocean strategy”.
Low-end disruption is exemplified by Southwest Airlines and BIC Disposable Razors. Southwest Airlines disrupted the aviation industry by focusing on providing basic, reliable, and cost-effective air travel, appealing to price-sensitive customers and those who might opt for alternative transportation. BIC, on the other hand, introduced affordable disposable razors, offering a satisfactory solution for customers unwilling to pay a premium for high-end razors, thereby securing a substantial market share.

In terms of new-market disruption, Tesla Motors and Coursera stand out. Tesla targeted environmentally conscious consumers, offering electric vehicles that didn’t compromise on performance or luxury, creating a new market for high-performance electric vehicles and prompting other manufacturers to expedite their EV programs. After introducing the high-end luxury cars, Tesla subsequently moved down market and even announced in the “Master Plan Part 3” that they plan to release a $25k electric car. Coursera disrupted the traditional educational model by providing online courses from renowned universities to a global audience, creating a new market for online education.

The Blue Ocean Strategy, which is somewhat related to new-market disruption, emphasizes innovating and creating new demand in unexplored market areas, or “Blue Oceans”, instead of competing in saturated markets, or “Red Oceans”. An example of this strategy is the Nintendo Wii, which carved out a new market space by targeting casual gamers with simpler, family-friendly games and innovative controllers, thereby reaching an entirely new demographic of consumers and avoiding direct competition with powerful gaming consoles like Xbox and PlayStation.
The disruptive innovation process often plays out like so:
- Introduction: The innovation is introduced, often with skepticism from established players.
- Evolution: The innovation evolves and improves, gradually becoming more appealing to a wider customer base.
- Disruption: The innovation becomes good enough to meet the needs of most customers, disrupting the status quo.
- Domination: The innovators often come to dominate the market, replacing the previous incumbents.
Technological advancements typically undergo an S-curve progression, as seen with smartphones, which experienced slow initial adoption, followed by rapid uptake, and eventually, market saturation.

Companies often align innovations with their existing value networks, ensuring new products resonate with their established customer base, like how Apple’s product ecosystem is meticulously designed to ensure customer retention and continuous engagement.
The implications of disruptive innovation are profound, with established companies, such as Kodak, often facing dilemmas and organizational inertia in adopting new technologies due to a deep-rooted focus on existing offerings and customer bases.
To navigate through disruptive waters, incumbents might employ strategies like establishing separate units dedicated to innovation, akin to how Google operates Alphabet to explore varied ventures, adopting agile methodologies for nimble operations, and maintaining a relentless focus on evolving customer needs to stay relevant and competitive in the market.
 Here’s my personal key take-away (not financial advice):
Here’s my personal key take-away (not financial advice):
It is tough to create a huge disruptive startup. It is easy to disrupt a tiny niche.
A great strategy that I found extremely profitable is to focus on a tiny niche within your career, keep optimizing daily, and invest your income in star businesses, i.e., disruptive innovation companies in high-growth markets (>10% per year) that are also market leaders.
Only invest in companies or opportunities that are both, in a high-growth market and leader of this market.
Bitcoin, for example, is the leader of a high-growth market (=digital store of value). Tesla, another example, is the leader of a high-growth market (=autonomous electric vehicles).
A Short Primer on the Star Principle — And How It’ll Make You Rich
The Star Principle, articulated by Richard Koch, underscores the potency of investing in or creating a ‘star venture’ to amass wealth and success in business.

A star venture is characterized by two pivotal attributes: (1) it is a leader in a high-growth market and (2) it operates within a niche that is expanding rapidly.
The allure of a star business emanates from its ability to combine niche leadership with high niche growth, enabling it to potentially command price premiums, lower costs, and subsequently, attain higher profits and cash flow.
The principle asserts that positioning is the key to success, provided that the positioning is truly exceptional and the venture is a star business. However, it’s imperative to note that star ventures are not devoid of risks; the primary pitfall being the loss of leadership within its niche, which can drastically diminish its value.
While star ventures are relatively rare, with perhaps one in twenty startups being a star, they are not so scarce that they cannot be discovered or created with thoughtful consideration and patience.
The principle emphasizes that whether you are an employee, an aspiring venture leader, or an investor, aligning yourself with a star venture can pave the way to a prosperous and enriched life.

Here’s a list of 20 example star businesses from the past (some are still stars  ):
):
- Apple: Dominates various tech niches, offering premium products that command higher prices.
- Amazon: A leader in e-commerce and cloud computing, consistently expanding into new markets.
- Google (Alphabet): Dominates the search engine market and has successful ventures like YouTube.
- Facebook (Meta): Leads in social media through platforms like Facebook, Instagram, and WhatsApp.
- Microsoft: A leader in software, cloud services, and hardware, with a vast, growing ecosystem.
- Tesla: Revolutionizing the electric vehicle market and autonomous technologies. The bot!
- Netflix: A dominant player in the streaming service industry, with a massive global subscriber base.
- Alibaba: A leader in e-commerce, cloud computing, and various other sectors in China and globally.
- Shopify: A giant in the e-commerce platform space, enabling myriad online stores globally.
- Zoom: Became essential for virtual communication, especially during the pandemic, and continues to grow.
- Spotify: Leading the music streaming industry with a vast library and substantial subscriber base.
- PayPal: A major player in the digital payments space, facilitating global e-commerce.
- Adobe: Dominates several software niches, including graphic design and document management.
- Salesforce: Leads in customer relationship management (CRM) software and platform technology.
- NVIDIA: A dominant force in GPUs, expanding into AI, machine learning, and autonomous vehicles.
- Airbnb: Revolutionized the hospitality industry, becoming a go-to platform for home-sharing.
- Square: Innovating in the financial and mobile payment sectors, providing solutions for small businesses.
- Uber: Despite controversies, it remains a significant player in ride-hailing and has expanded into food delivery.
- Tencent: A conglomerate leader in various sectors, including social media, gaming, and fintech, particularly in China.
- Samsung: A leader in various tech niches, including smartphones, semiconductors, and consumer electronics.
These businesses have demonstrated leadership in their respective niches and have experienced significant growth, aligning with the Star Principle’s criteria of operating in high-growth markets and being a leader in those markets.
Let’s dive into some practical strategies you can use as a small coding business owner to become more innovative, possibly disruptive in a step-by-step manner:
9-Step Guide to Leverage the Disruptive Innovation Model for a Small Coding Business

Step 1: Identify Underserved Needs
Imagine embarking on a journey to create a startup named “ChatHealer,” an online platform that uses Large Language Models (LLMs) and the OpenAI API to provide instant, empathetic, and anonymous conversational support for individuals experiencing stress or emotional challenges.
Step 2: Define Your Value Proposition
In the initial phase, identifying underserved needs is crucial. A thorough market research might reveal that there’s a gap in providing immediate, non-clinical emotional support to individuals in a highly accessible and non-judgmental platform.
The unique value proposition of ChatHealer would be its ability to offer instant, 24/7 emotional support through intelligent and empathetic conversational agents, ensuring user anonymity and privacy.
Step 3: Develop a Minimum Viable Product (MVP) to Validate and Iterate
The development of a Minimum Viable Product (MVP) would involve creating a basic version of ChatHealer, focusing on core functionalities like user authentication, basic conversational abilities, and ensuring data security. The MVP would be introduced to a select group of users, and their feedback would be paramount in validating and iterating the product, ensuring it aligns with user expectations and experiences.

 Recommended: Minimum Viable Product (MVP) in Software Development — Why Stealth Sucks
Recommended: Minimum Viable Product (MVP) in Software Development — Why Stealth Sucks
Step 4: Utilize LLMs and AI to Scale Labor and Find a Business Model
Leveraging LLMs and AI, ChatHealer could enhance its conversational agents to understand and respond to user inputs more empathetically and contextually, providing a semblance of genuine human interaction.
The business model might adopt a freemium approach, offering basic conversational support for free while providing a premium subscription that includes additional features like personalized emotional support journeys, and perhaps, priority access to human professionals.
Step 5: Focus on Customer Experience and Scale Gradually

Ensuring a seamless and supportive customer experience would be pivotal, as the nature of ChatHealer demands a safe and nurturing environment. As the platform gains traction, gradual scaling would involve introducing ChatHealer to wider demographics and possibly integrating multilingual support to cater to a global audience.
Step 6: Continuous Improvements
Continuous improvement would be embedded in ChatHealer’s operations, ensuring that the platform evolves with technological advancements and user needs. Building partnerships, perhaps with mental health professionals and organizations, could enhance its credibility and provide a pathway for users to access further support if needed.
Step 7: Manage Finances Wisely
Prudent financial management would ensure that funds are judiciously utilized, maintaining a balance between technological development, marketing, and operations. Cultivating a culture of innovation within the team ensures that ChatHealer remains at the forefront of technological and therapeutic advancements, always exploring new ways to provide support to its users.
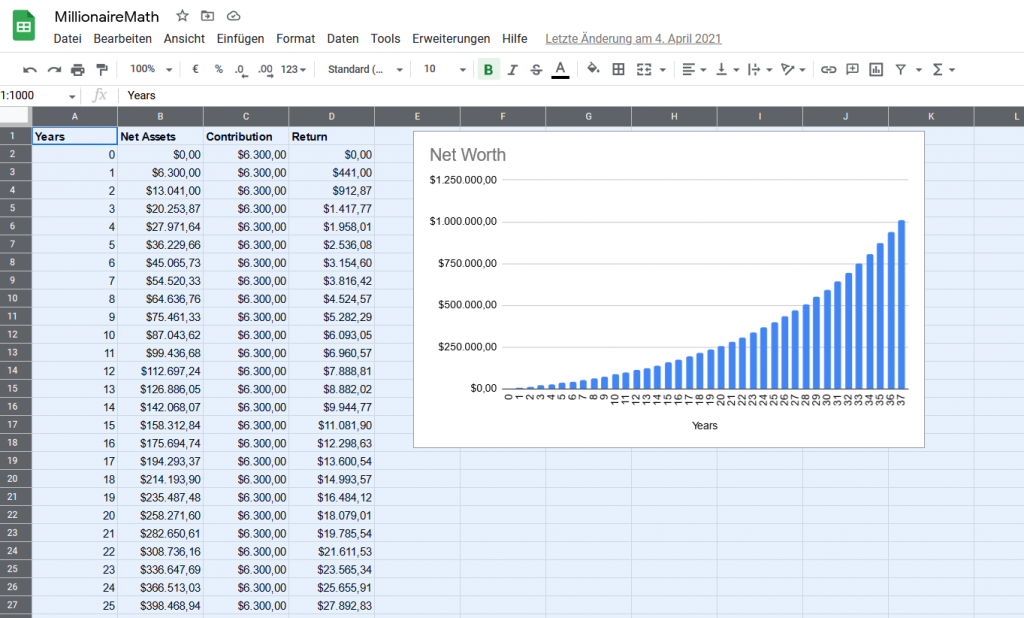
Recommended: The Math of Becoming a Millionaire in 13 Years
Step 8: Adaptability and Compliance
Adaptability would be key, as ChatHealer would need to be ready to pivot its strategies and offerings in response to user needs, technological advancements, and market trends. Ensuring that all operations, especially data handling and user interactions, adhere to legal and compliance standards would be paramount to maintain user trust and regulatory adherence.
Step 9: Measure and Analyze Throughout the Process
Lastly, employing analytics to measure and analyze user engagement, subscription conversions, and user feedback would be instrumental in shaping ChatHealer’s future strategies and innovations, ensuring that it not only remains a disruptive innovation but also a sustained, valuable service in the emotional support domain.
Case Study: Is Uber a Disruptive Innovation?
In this section, we will explore whether Uber is a disruptive innovation by examining its origins and how its quality compares to the mainstream market expectations.
Disruptive Innovations Start with Low-End or New-Market Footholds
Disruptive innovations typically begin in low-end or new-market footholds, as incumbents often focus on their most profitable and demanding customers. This focus can lead to less attention being paid to less-demanding customers, allowing disruptors to introduce products that cater to these neglected market segments.
However, Uber did not originate with either a low-end or new-market foothold. It did not start by targeting non-consumers or finding a low-end opportunity. Instead, Uber was launched in San Francisco, which already had a well-established taxi market. Its primary customers were individuals who already had the habit of hiring rides. Therefore, Uber did not follow the typical pattern of disruptive innovations that begin with low-end or new-market footholds.
Quality Must Align with Mainstream Expectations in Disruptive Innovations
Disruptive innovations are initially perceived as inferior in comparison to the offerings by established companies. Mainstream customers are hesitant to adopt these new, typically cheaper, alternatives until their quality satisfies their expectations.
In the case of Uber, most elements of its strategy appear to be sustaining innovations. Its service is often regarded as equal or superior to existing taxi services, with convenient booking, cashless payments, and a passenger rating system. Additionally, Uber generally offers competitive pricing and reliable service. In response to Uber, established taxi companies have implemented similar technologies and challenged the legality of some of Uber’s offerings.
Based on these factors, Uber cannot be considered a true disruptive innovation. While it has certainly impacted the taxi market and incited changes among traditional taxi companies, it did not originate from classic low-end or new-market footholds, and its service quality aligns with mainstream expectations rather than being perceived as initially inferior.
Frequently Asked Questions
What makes disruptive innovation different from regular innovations?
Disruptive innovation refers to a process where a smaller company with fewer resources challenges established businesses by entering at the bottom of the market and moving up-market. This is different from traditional or incremental innovations, which usually improve existing products or services for existing customers.
Can you give some examples of disruptive innovation in the healthcare sector?
Some examples of disruptive innovation in healthcare include:
- Telemedicine: Remote consultations through video calls, making healthcare services more accessible.
- Wearable health technology: Wearable devices that monitor and track health data, empowering individuals to take control of their health.
- Electronic health records (EHR): Digitizing patient records for more efficient and secure management of information.
Which companies have successfully implemented disruptive innovation?
Some well-known companies that implemented disruptive innovation strategies include:
- Netflix (transforming the way we consume video content)
- Uber (redefining transportation services)
- Airbnb (disrupting the hospitality industry)
- Slack (changing team communication and collaboration)
Could you share some low-end disruptive innovation examples?
Low-end disruption refers to innovations targeting customers who are not well-served by the incumbent companies due to high prices or complex products. Examples include:
- IKEA (providing affordable and stylish furniture)
- Southwest Airlines (offering low-cost air travel)
- Xiaomi (manufacturing and selling high-quality smartphones at affordable prices)
What is the process for introducing disruptive innovations?
Launching disruptive innovations typically involves the following steps:
- Identify an underserved market segment or new niche.
- Develop a cost-effective, simple, and efficient solution targeting this segment.
- Iterate and improve the product or service offering as you learn more about customers and the market.
- Gradually move up-market, improving the product or service as it gains traction and market share.
Can you provide examples of new market disruptions?
New market disruptions typically create entirely new markets that did not exist before. Examples include:
- E-commerce platforms like Amazon (creating a massive online marketplace)
- Social media platforms like Facebook (connecting people worldwide and creating an advertising market)
- Streaming music services like Spotify (transforming how individuals listen to music and generating revenue through subscriptions and ads)
If you want to keep learning disruptive technologies, why not becoming an expert prompt engineer with our Finxter Academy Courses (all-you-can-learn) such as this one: 

The post Disruptive Innovation – A Friendly Guide for Small Coding Startups appeared first on Be on the Right Side of Change.
 If a value is a dictionary, the function calls itself.
If a value is a dictionary, the function calls itself. 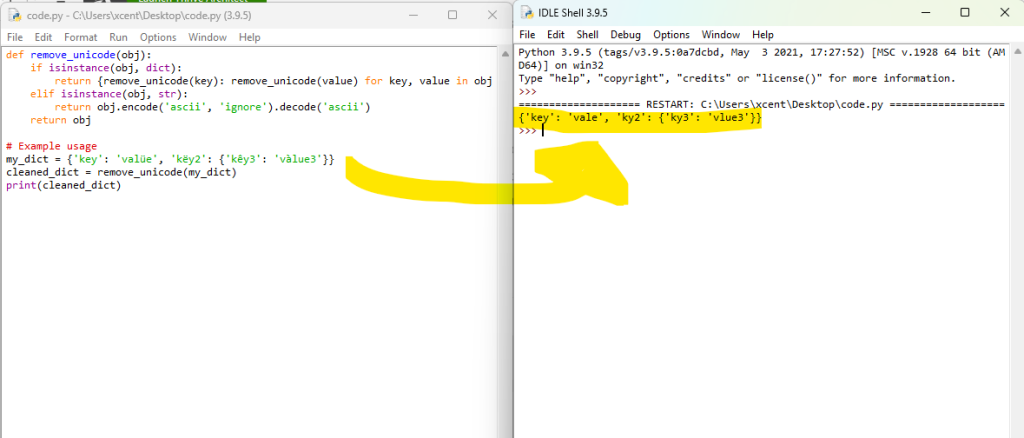



 ). This diversity is because Python supports Unicode characters to allow for broader text representation and internationalization.
). This diversity is because Python supports Unicode characters to allow for broader text representation and internationalization.






 GPT-4V could explain why a picture was funny by talking about different parts of the image and their connections. The meme in the picture has words on it, which GPT-4V read to help make its answer. However, it made an error. It wrongly said the fried chicken in the image was called “NVIDIA BURGER” instead of “GPU”.
GPT-4V could explain why a picture was funny by talking about different parts of the image and their connections. The meme in the picture has words on it, which GPT-4V read to help make its answer. However, it made an error. It wrongly said the fried chicken in the image was called “NVIDIA BURGER” instead of “GPU”. OpenAI’s GPT-4 with Vision (GPT-4V) represents a significant advancement in artificial intelligence, enabling the analysis of image inputs alongside text.
OpenAI’s GPT-4 with Vision (GPT-4V) represents a significant advancement in artificial intelligence, enabling the analysis of image inputs alongside text.












 like so:
like so:




 Python,
Python, 
 Langchain,
Langchain,  Pinecone, and a whole stack of highly
Pinecone, and a whole stack of highly 
 practical tools of exponential coders in a post-ChatGPT world.
practical tools of exponential coders in a post-ChatGPT world. and
and  on a
on a  day! \u200b \u1234"}' # Load JSON data
data = json.loads(json_str) # Remove all Unicode characters from the value
data['text'] = re.sub(r'[^\x00-\x7F]+', '', data['text']) # Convert back to JSON string
new_json_str = json.dumps(data) print(new_json_str)
# {"text": "I love and on a day! "}
day! \u200b \u1234"}' # Load JSON data
data = json.loads(json_str) # Remove all Unicode characters from the value
data['text'] = re.sub(r'[^\x00-\x7F]+', '', data['text']) # Convert back to JSON string
new_json_str = json.dumps(data) print(new_json_str)
# {"text": "I love and on a day! "}

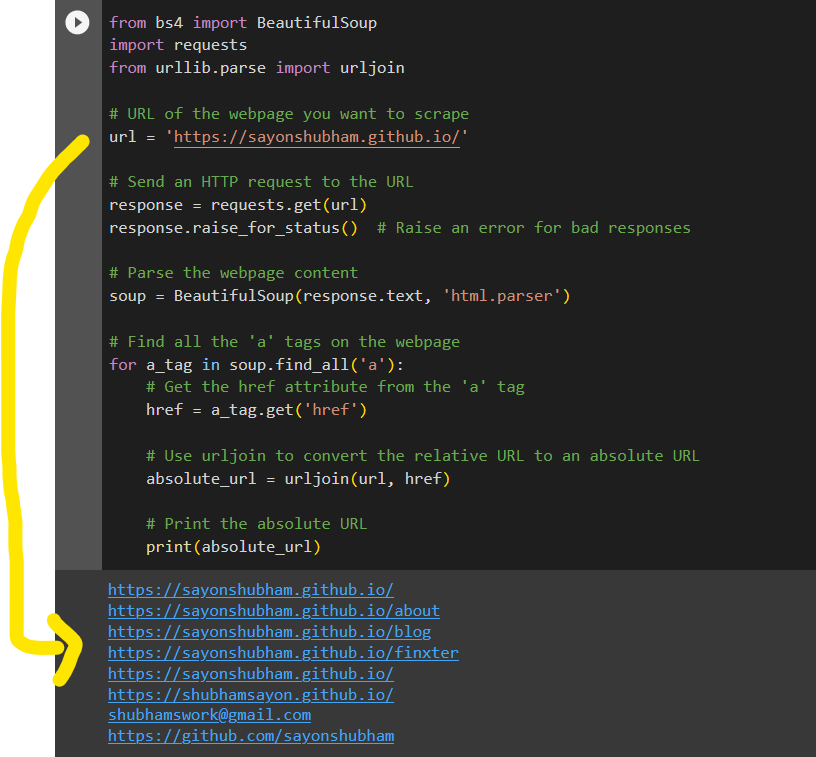
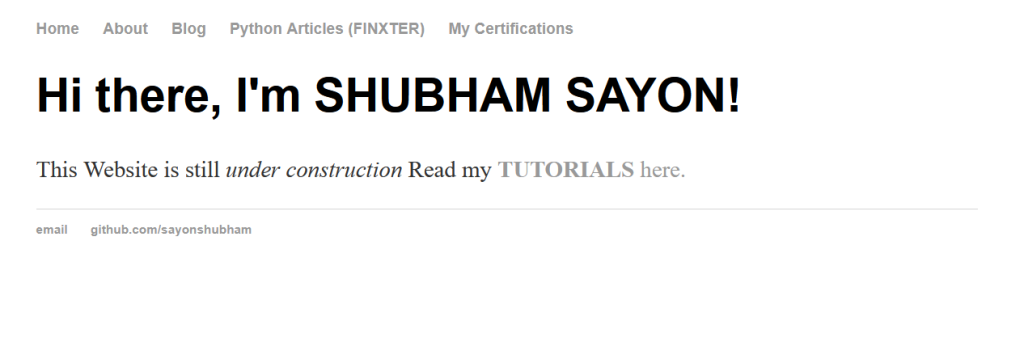












 For the best open-source LLM, consider using
For the best open-source LLM, consider using 

