The rise of microservices-oriented architecture brought us new development paradigms and mantras about independent development and decoupling. In such a scenario, we have to deal with a situation where we aim for independence, but we still need to react to state changes in different enterprise domains.
I’ll use a simple and typical example in order to show what we’re talking about. Imagine the development of two independent microservices: Order and User. We designed them to expose a REST interface and to each use a separate database, as shown in Figure 1:
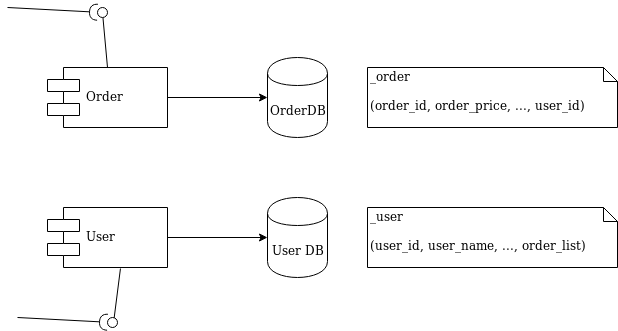
Figure 1: Order and User microservices.
We must notify the User domain about any change happening in the Order domain. To do this in the example, we need to update the order_list. For this reason, we’ve modeled the User REST service with addOrder and deleteOrder operations.
Solution 1: Queue decoupling
The first solution to consider is adding a queue between the services. Order will publish events that User will eventually process, as shown in Figure 2:
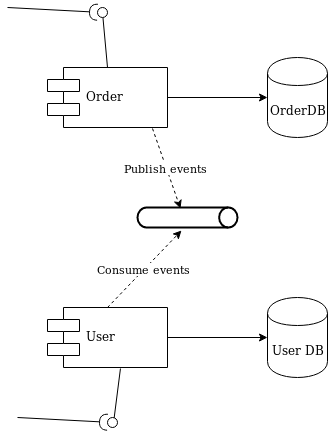
Figure 2: Decoupling with a queue.
This is a fair design. However, if you don’t use the right middleware you will mix a lot of infrastructure code into your domain logic. Now that you have queues, you must develop producer and consumer logic. You also have to take care of transactions. The problem is to make sure that every event ends up correctly in both the Order database and in the queue.
Solution 2: Change data capture decoupling
Let me introduce an alternative solution that handles all of that work without your touching any line of your microservices code. I’ll use Debezium and Apache Camel to capture data changes on Order and trigger certain actions on User. Debezium is a log-based data change capture middleware. Camel is an integration framework that simplifies the integration between a source (Order) and a destination (User), as shown in Figure 3:
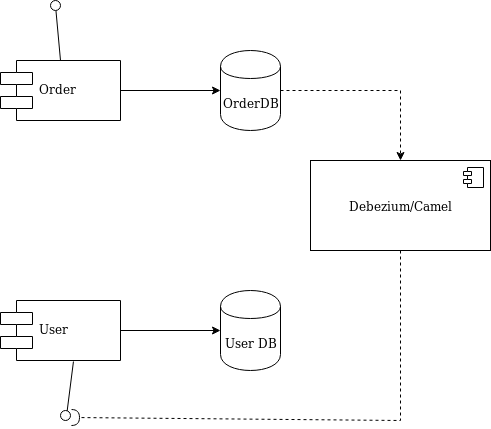
Figure 3: Decoupling with Debezium and Camel.
Debezium is in charge of capturing any data change happening in the Order domain and publishing it to a topic. Then a Camel consumer can pick that event and make a REST call to the User API to perform the necessary action expected by its domain (in our simple case, update the list).
Decoupling with Debezium and Camel
I’ve prepared a simple demo with all of the components we need to run the example above. You can find this demo in this GitHub repo. The only part we need to develop is represented by the following source code:
public class MyRouteBuilder extends RouteBuilder { public void configure() { from("debezium:mysql?name=my-sql-connector" + "&databaseServerId=1" + "&databaseHostName=localhost" + "&databaseUser=debezium" + "&databasePassword=dbz" + "&databaseServerName=my-app-connector" + "&databaseHistoryFileName=/tmp/dbhistory.dat" + "&databaseWhitelist=debezium" + "&tableWhitelist=debezium._order" + "&offsetStorageFileName=/tmp/offset.dat") .choice() .when(header(DebeziumConstants.HEADER_OPERATION).isEqualTo("c")) .process(new AfterStructToOrderTranslator()) .to("rest-swagger:http://localhost:8082/v2/api-docs#addOrderUsingPOST") .when(header(DebeziumConstants.HEADER_OPERATION).isEqualTo("d")) .process(new BeforeStructToOrderTranslator()) .to("rest-swagger:http://localhost:8082/v2/api-docs#deleteOrderUsingDELETE") .log("Response : ${body}"); } }
That’s it. Really. We don’t need anything else.
Apache Camel has a Debezium component that can hook up a MySQL database and use Debezium embedded engine. The source endpoint configuration provides the parameters needed by Debezium to note any change happening in the debezium._order table. Debezium streams the events according to a JSON-defined format, so you know what kind of information to expect. For each event, you will get the information as it was before and after the event occurs, plus a few useful pieces of meta-information.
Thanks to Camel’s content-based router, we can either call the addOrderUsingPOST or deleteOrderUsingDELETE operation. You only have to develop a message translator that can convert the message coming from Debezium:
public class AfterStructToOrderTranslator implements Processor { private static final String EXPECTED_BODY_FORMAT = "{\"userId\":%d,\"orderId\":%d}"; public void process(Exchange exchange) throws Exception { final Map value = exchange.getMessage().getBody(Map.class); // Convert and set body int userId = (int) value.get("user_id"); int orderId = (int) value.get("order_id"); exchange.getIn().setHeader("userId", userId); exchange.getIn().setHeader("orderId", orderId); exchange.getIn().setBody(String.format(EXPECTED_BODY_FORMAT, userId, orderId)); } }
Notice that we did not touch any of the base code for Order or User. Now, turn off the Debezium process to simulate downtime. You will see that it can recover all events as soon as it turns back on!
You can run the example provided by following the instructions on this GitHub repo.
Caveat
The example illustrated here uses Debezium’s embedded mode. For more consistent solutions, consider using the Kafka connect mode instead, or tuning the embedded engine accordingly.

The post Decoupling microservices with Apache Camel and Debezium appeared first on Red Hat Developer.